Preserving privacy with data synthesis
Legitimate privacy concerns often limit access to large datasets, either by requiring a very lengthy approval process, or by allowing access to only a small number of dedicated servers (e.g., within a hospital). However, to unleash the full power of various machine learning techniques, we need to find ways to share and pool data among research groups, while adhering to strict measures of confidentiality.
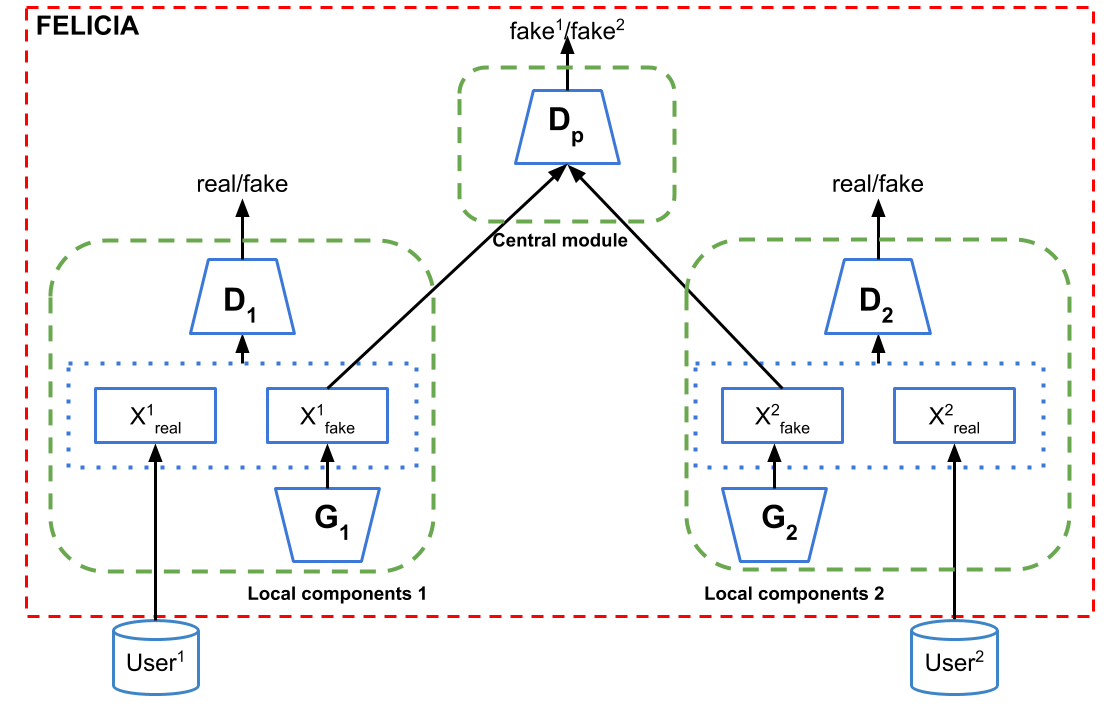
In collaboration with Microsoft AI for Good Lab, our group is investigating the utility/privacy tradeoff of synthetic data generation. We are interested in broad, theory-backed approaches that apply to real-life situations, especially those in the healthcare setting. Our aim is to allow researchers to access useful but sensitive data without violating patient privacy. We are exploring private synthetic data generation frameworks which can provide robust protection against privacy attacks, while still providing utility close to that of real data. In our most recent project, we introduced FELICIA (FEderated LearnIng with a CentralIzed Adversary) a generative mechanism enabling collaborative learning for decentralized users without direct access to their data.